RULECOMPILE - Undocumented Ghidra decompiler rule language
Or “How I got annoyed by a poor decompilation so I unearthed a hidden Ghidra feature”
TLDR: there is a (undocumented and disabled by default) feature in the Ghidra decompiler that lets you create your own decompiler passes, using a custom DSL. I leverage it to write a deobfuscation rule for a simple obfuscation technique.
- Story Setup - introduction and problem statement
- Decompiler 101 - building and using Ghidra decompiler directly
- RULECOMPILE - a curious #define flag from the decompiler source
- A forgotten language of dragons - reverse-engineering a forgotten code pattern matching DSL
- How to train your dragon - how to write a rule that is actually useful
- Conclusion - parting thoughts
Story setup
It all started with this one missed deobfuscation:
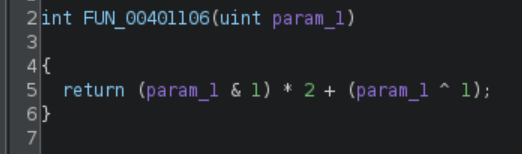
Do you know what this function does? Take a few seconds to think about it, if you want.
…
…
Yes, this is just a simple incrementation. Consider the lowest bit of param_1:
- if
param1 & 1is 0, then(param1 & 1) * 2is zero too, andparam1 ^ 1is justparam1 + 1. - if
param1 & 1is 1, then(param1 & 1) * 2equals 2, butparam1 ^ 1is nowparam1 - 1, so the result isparam1 + 1again.
What can we do to clean this up? There are several possible courses of action. Let’s consider them one by one:
Ignore the problem
We can ignore the problem entirely and live with it - the pattern is easy to spot, and we already recognise it. This is probably the sanest option. As you may guess, I didn’t pursue it, though maybe I should.
Fix it with a script
Maybe we can write a Ghidra script that will fix the decompilation?1 Well, no. Unfortunately, Ghidra is not very flexible when one wants to influence the decompiler. The decompiler is almost a blackbox that we can just nudge in the right directions. Almost all analysis happen in there:
- Raw bytes are disassembled and translated to Pcode using SLEIGH
- Pcode is optimized and lifted to high Pcode2
- High-level programing language structures - loops, conditionals, control flow - are recovered3
- A tokenized version of decompiled source code is generated and sent back to Ghidra.
With few exceptions, none of these steps can be influenced by a script/extension/program annotations.
Patch the assembly code
This one is actually doable - we can patch the binary assembly code and replace it that whols section with incrementation. But that has a lot of downsides:
- Our code is now architecture dependent - even though the rule is very generic, and Ghidra works with dozens of architectures thanks to PCode.
- It may be very hard to match the obfuscation pattern - especially if the code we see is already a simplified version of the original, much more obfuscated code.
- We have to patch the binary, which is invasive and may make the binary unrunnable.
In practice this is what I do when I have to, but I wish there was a better way.
Improve the decompiler and submit a pull request
In principle, this is the best option. Ghidra is open-source, so we can grab the source code, make our changes, and maybe submit a pull request.
The problem is that decompiler is a complex piece of software, so that’s a non-trivial task. A large upside is that we can submit our changes to the official Ghidra repository as a pull request, so that everyone can benefit from them. Unfortunately, there’s not many people who can review such a pull request, so they tend to wait forever for merging. So, unless you’re very dedicated, there is no way to share your improvements with the community.
What if there was an easier way?
Decompiler 101
Let’s take a closer look at the decompiler. I didn’t get around to post about it yet4,
but long story short: there is a internal debugger tool, not build
by default, that you can use to peek into the decompiler internals. It’s called
decomp_dbg, and the best public source of information about it right now is
this nccgroup blog post.
and this Github issue.
I’ll update this section with a link to a more detailed post when/if I write it,
but for now the point is that you can go to Ghidra/Features/Decompiler/src/decompile/cpp,
run make decomp_dbg, and get a decomp_dbg binary. For this blog post, I will use the
ghidra 11.2.1 release
(Ghidra_11.1.2_build tag in the git repository).
Let’s try it. First, download this obfuscated binary.
You can check it in Ghidra - the main function is just return argc,
but obfuscated with the technique I mentioned above. There is an option
to “debug function decompilation” in Ghidra, which we can use to analyse
the decompilation process:
But we won’t actually use it in this blog post5. So let’s run decomp_dbg on the binary directly:
$ set -x SLEIGHHOME ~/opt/ghidra # export SLEIGHHOME=... for bash users
$ ./decomp_dbg
[decomp]> load file /home/you/xyz/obfuscated
[decomp]> load addr 0x0101129
Low-level ERROR: Unable to load 512 bytes at r0x00101129
Unable to proceed with function: func_0x00101129
Wait, what? This worked for me before. After a quick look at the source code and a lucky guess, another try:
$ set -x SLEIGHHOME ~/opt/ghidra # export SLEIGHHOME=... for bash users
$ ./decomp_dbg
[decomp]> load file /home/you/xyz/obfuscated
[decomp]> adjust vma 0x100000
[decomp]> load addr 0x0101129
Function func_0x00101129: 0x00101129
Now we are free to decompile to our heart’s content:
[decomp]> decompile
Decompiling func_0x00101129
Decompilation complete
[decomp]> print C
int4 func_0x00101129(uint4 param_1)
{
return (param_1 & 1) * 2 + (param_1 ^ 1);
}
RULECOMPILE
This begs the question6, what other features are possible? The list is in the ifacedecomp.cc file. But wait, what is this?
status->registerCom(new IfcLoadTestFile(), "load","test","file");
status->registerCom(new IfcListTestCommands(), "list","test","commands");
status->registerCom(new IfcExecuteTestCommand(), "execute","test","command");
#ifdef CPUI_RULECOMPILE
status->registerCom(new IfcParseRule(),"parse","rule");
status->registerCom(new IfcExperimentalRules(),"experimental","rules");
#endif
status->registerCom(new IfcContinue(),"continue");
Two commands are fenced behind a feature flag - undocumented and not enabled by default.
As of today, googling CPUI_RULECOMPILE returns only three results,
two of them are source code from the official Github and the last one from a source code mirror.7
Let’s try to enable it! Just add the flag to the makefile and build:
$ git diff
diff --git a/Ghidra/Features/Decompiler/src/decompile/cpp/Makefile b/Ghidra/Features/Decompiler/src/decompile/cpp/Makefile
index ead17e0..3946e17 100755
--- a/Ghidra/Features/Decompiler/src/decompile/cpp/Makefile
+++ b/Ghidra/Features/Decompiler/src/decompile/cpp/Makefile
@@ -38,7 +38,7 @@ endif
CXX=g++ -std=c++11
# Debug flags
-DBG_CXXFLAGS=-g -Wall -Wno-sign-compare
+DBG_CXXFLAGS=-g -Wall -Wno-sign-compare -DCPUI_RULECOMPILE
#DBG_CXXFLAGS=-g -pg -Wall -Wno-sign-compare
#DBG_CXXFLAGS=-g -fprofile-arcs -ftest-coverage -Wall -Wno-sign-compare
$ make decomp_dbg -j 8
Annnnd it doesn’t work - we get tons of compiler errors:
architecture.cc: In member function ‘void ghidra::Architecture::decodeDynamicRule(ghidra::Decoder&)’:
architecture.cc:729:57: error: ‘el’ was not declared in this scope
729 | Rule *dynrule = RuleGeneric::build(rulename,groupname,el->getContent());
In copy constructor ‘ghidra::Address::Address(const ghidra::Address&)’,
inlined from ‘ghidra::rangemap<ghidra::ScopeMapper>::AddrRange::AddrRange(ghidra::rangemap<ghidra::ScopeMapper>::AddrRange&&)’ at rangemap.hh:76:9,
inlined from ‘void std::__new_allocator<_Tp>::construct(_Up*, _Args&& ...) [with _Up = ghidra::rangemap<ghidra::ScopeMapper>::AddrRange; _Args = {ghidra::rangemap<ghidra::ScopeMapper>::AddrRange}; _Tp = std::_Rb_tree_node<ghidra::rangem
ap<ghidra::ScopeMapper>::AddrRange>]’ at /nix/store/4krab2h0hd4wvxxmscxrw21pl77j4i7j-gcc-13.3.0/include/c++/13.3.0/bits/new_allocator.h:191:4,
inlined from ‘static void std::allocator_traits<std::allocator<_CharT> >::construct(allocator_type&, _Up*, _Args&& ...) [with _Up = ghidra::rangemap<ghidra::ScopeMapper>::AddrRange; _Args = {ghidra::rangemap<ghidra::ScopeMapper>::AddrRa
nge}; _Tp = std::_Rb_tree_node<ghidra::rangemap<ghidra::ScopeMapper>::AddrRange>]’ at /nix/store/4krab2h0hd4wvxxmscxrw21pl77j4i7j-gcc-13.3.0/include/c++/13.3.0/bits/alloc_traits.h:538:17,
Apparently nobody tried to compile with this feature enabled in a long time. Let’s try to fix it.
First of all, we don’t have ruleparse.cc nor ruleparse.hh files, but we have ruleparse.y.
For those of you who attended a compiler course, this is a YACC file and we can build it with bison:
$ make ruleparse.cc ruleparse.hh
bison -p ruleparse -d -o ruleparse.cc ruleparse.y
Then let’s hunt copilation errors one by one. I’ll spare you the boring details, and just show my ugly patch:
diff --git a/Ghidra/Features/Decompiler/src/decompile/cpp/architecture.cc b/Ghidra/Features/Decompiler/src/decompile/cpp/architecture.cc
index 494d160..8ac2725 100755
--- a/Ghidra/Features/Decompiler/src/decompile/cpp/architecture.cc
+++ b/Ghidra/Features/Decompiler/src/decompile/cpp/architecture.cc
@@ -726,7 +726,7 @@ void Architecture::decodeDynamicRule(Decoder &decoder)
throw LowlevelError("Dynamic rule has no group");
if (!enabled) return;
#ifdef CPUI_RULECOMPILE
- Rule *dynrule = RuleGeneric::build(rulename,groupname,el->getContent());
+ Rule *dynrule = RuleGeneric::build(rulename,groupname, (reinterpret_cast<XmlDecode*>(&decoder))->getCurrentXmlElement()->getContent());
extra_pool_rules.push_back(dynrule);
#else
throw LowlevelError("Dynamic rules have not been enabled for this decompiler");
diff --git a/Ghidra/Features/Decompiler/src/decompile/cpp/rulecompile.cc b/Ghidra/Features/Decompiler/src/decompile/cpp/rulecompile.cc
index fe8a413..f346ce9 100755
--- a/Ghidra/Features/Decompiler/src/decompile/cpp/rulecompile.cc
+++ b/Ghidra/Features/Decompiler/src/decompile/cpp/rulecompile.cc
@@ -14,14 +14,19 @@
* limitations under the License.
*/
#ifdef CPUI_RULECOMPILE
-#include "rulecompile.hh"
-#include "ruleparse.hh"
+
+#include "types.h"
+#include <string>
+using std::string;
+using namespace ghidra;
+
+
+int4 ruleparsedebug;
+extern int4 ruleparseparse(void);
namespace ghidra {
RuleCompile *rulecompile;
-extern int4 ruleparsedebug;
-extern int4 ruleparseparse(void);
class MyLoadImage : public LoadImage { // Dummy loadimage
public:
diff --git a/Ghidra/Features/Decompiler/src/decompile/cpp/ruleparse.y b/Ghidra/Features/Decompiler/src/decompile/cpp/ruleparse.y
index 3d3ced6..32f42ff 100755
--- a/Ghidra/Features/Decompiler/src/decompile/cpp/ruleparse.y
+++ b/Ghidra/Features/Decompiler/src/decompile/cpp/ruleparse.y
@@ -15,11 +15,19 @@
*/
%{
#ifdef CPUI_RULECOMPILE
+
+#include "types.h"
+#include <string>
+using std::string;
+
#include "rulecompile.hh"
#define YYERROR_VERBOSE
+using namespace ghidra;
+namespace ghidra {
extern RuleCompile *rulecompile;
+}
extern int ruleparselex(void);
extern int ruleparseerror(const char *str);
NB: these are just hacks to make it compile, not a proper fix.
Anyway, with these fixes we can compile decomp_dbg and run it:
$ set -x SLEIGHHOME ~/opt/ghidra # export SLEIGHHOME=... for bash users
$ ./decomp_dbg
[decomp]> experimental rules
Command parsing error: Missing name of file containing experimental rules
Ok… now what?
Into the XML hell
Since there’s no documentation, we have to figure out how to use this by reading
the source code. I’ll focus on the experimental rules command (it is used
to load and enable the decompiler rules). If we try to load a random file, we get a syntax error:
[decomp]> experimental rules /etc/passwd
Successfully registered experimental file /etc/passwd
[decomp]> [decomp]> load file /home/you/xyz/obfuscated
ERROR: Invalid command
[decomp]> load file /home/you/xyz/obfuscated
Trying to parse /etc/passwd for experimental rules
syntax error
Skipping experimental rules
/home/you/xyz/obfuscated successfully loaded: Intel/AMD 64-bit x86
Let’s dig into a source code:
*status->optr << "Trying to parse " << dcp->experimental_file << " for experimental rules" << endl;
try {
Element *root = store.openDocument(dcp->experimental_file)->getRoot();
if (root->getName() == "experimental_rules") store.registerTag(root);
OK, so we need XML. By digging further, we deduce that the file should look like this:
<experimental_rules>
<rule name="rule_name" group="group_name" enable="true">
???
</rule>
</experimental_rules>
Rule name is arbitrary, and group may be analysis for example (this determines when
our rule gets to execute). But what do we put inside? We have to read the YACC grammar to understand the syntax. The grammar,
untouched since the initial Ghidra release, is
here.
It should look familiar if you ever wrote a BNF parser. For example,
fullrule: '{' statementlist actionlist '}'
Means that the full rule consists of a literal { followed by a statementlist followed by an actionlist
followed by a literal }. Similarly, we can investigate statementlist and actionlist, and so on.
There is one thing that can help us - a comment left in rulecompile.hh:
/*
Definition of the language
Identifiers start with 'o' for named pcodeops
'v' for named varnodes
'#' for named constants
A "statement" is a sequence of "steps", ending in a semicolon
Steps are sequential, proceeding left to right. Each step is either a
building step (which defines a new entity in terms of an existing entity), or a
constraint (which forces a condition to be true)
Building steps:
o -> v v is the output of o
o1 -> o2 o2 is a (named) copy of o1
o <- v v is ANY input of o
o <-(0) v v is input 0 of o
o <-(1) #c input 1 to o is a constant (now named c)
o <-(1) #0 input 1 to o is a constant with value 0
v <- o o is the defining op of v
v -> o o is ANY of the ops taking v as an input (may be inefficient)
v ->! o o is the one and only op taking v as input
v1 -> v2 v2 is a (named) copy of v1
Constraints:
o(+) o must have an opcode equal '+'
o1(== o2) o1 and o2 must be the same pcode op
o1(!= o2) o1 and o2 must not be the same pcode op
v1(== v2) v1 and v2 must be the same varnode
v1(!= v2) v1 and v2 must not be the same varnode
Statements can be grouped (into "statementlist") with parentheses '(' and ')'
There is an OR operator
'[' statementlist
| statementlist
...
']'
*/
That comment is not wrong, but it’s also incomplete. How do we actually create a complete rule? Let’s dig in deeper.
A forgotten language of dragons
First things first. We already know that
fullrule: '{' statementlist actionlist '}'
An abridged version of other important parts of the grammar (with C++ snippets removed) is:
statement: opnode ';' { ... }
| varnode ';' { ... }
| deadnode ';' { ... }
| '[' orgroupmid ']' { ... }
| '(' statementlist ')' { ... }
opnode: op_ident { ... }
| opnode '(' op_list ')' { ... }
...;
varnode: var_ident { ... }
| opnode LEFT_ARROW '(' INTB ')' var_ident { ... }
| opnode LEFT_ARROW var_ident { ... }
| opnode RIGHT_ARROW var_ident { ... }
| varnode '(' OP_INT_EQUAL var_ident ')' { ... }
...;
deadnode: opnode LEFT_ARROW '(' INTB ')' rhs_const { ... }
| opnode '=' op_ident { ... }
...;
actionlist: ACTION_TICK { ... }
| actionlist action { ... };
action: opnewnode ';' { ... }
| varnewnode ';' { ... }
| deadnewnode ';' { ... };
varnewnode: opnewnode DOUBLE_LEFT_ARROW '(' rhs_const ')' var_ident { ... }
...;
deadnewnode: opnewnode DOUBLE_LEFT_ARROW '(' rhs_const ')' rhs_const var_size { ... }
...;
So we have statements followed by ACTION_TICK followed by actions, and they both consist of “opnodes”, “varnodes” and “deadnodes”. The high-level structure of the experimental rule file is therefore:
{
statements
--
actions
}
And the possible statements are (among many others)
- Opnodes:
o1,o1(+), … - Varnodes:
o1 <- v1,o1 <-(1) v1,o1 -> v1,v1(== v2) - Deadnodes:
o1 <-(1) 123,o1 = o2, …
And for the actions (among many others):
- Opnewnodes:
o1 - Varnewnodes:
o1 <--(1) v1 - Deadnewnodes:
o1 <--(1) 123 4
Now that still doesn’t explain how to use it, but at least we can make a file that we can parse:
<experimental_rules>
<rule name="rule_name" group="group_name" enable="true">
{
o1(+) -> v1;
o2;
o3;
--
o2 < v1;
}
</rule>
</experimental_rules>
And it does parse:8
[decomp]> experimental rules /home/you/xyz/test.xml
Successfully registered experimental file /home/you/xyz/test.xml
[decomp]> load file /home/you/xyz/obfuscated
Trying to parse /home/you/xyz/test.xml for experimental rules
Unable to parse dynamic rule: rule_name
Could not create architecture
[decomp]> adjust vma 0x100000
Execution error: No load image present
[decomp]> load addr 0x0101129
fish: Process 914812, './decomp_dbg' from job 1, './decomp_dbg' terminated by signal SIGSEGV (Address boundary error)
Well, it’s not perfect yet, but we’re getting there.
How to train your dragon
Now the fun part. After reading the code and debugging segfaults (lots of segfaults9) with gdb, I figured out the rules:
- Statements describe what we want to match
- Actions describe how we want to transform the matched AST.
- Opnodes are the (pcode) operations we want to optimize
- Varnodes are, well, varnodes - the operands pcode operations take
- Deadnodes are not actually dead operations, they perform operations on defined varnodes and opnodes.
So in the statement section, we can write for example:
o1- match any operation (and name ito1).o1(+)- match any addition operation (and name ito1).v1- match any varnode (value) (and name itv1).v1(==v2)- match any varnodev1, as long as it’s equal tov2.o1 <- v1- match any operationo1, withv1being any of its operands.o1 <-(0) v1- match any operationo1, withv1being the first operand.o1(+) <- v1- match any addition operationo1, withv1being any of the oprands.o1 <-(1) 123- match any addition operationo1, with 123 being the second operand.o1 <- v2 <- o3- match any operationo1, withv1being any of its operands, ando3usingv1.
And so on. In the action section we define how we want to transform the AST, so for example:
o1 <--(0) v1- makev1the first operand ofo1.o1 <--(1) 42- make42the second operand ofo1.
There’s more, for example we can match on more complex conditions or create new nodes in the action section, but we won’t need that for this blog post. So a very simple rule that is not a NOP is:
{
o1(+);
--
o1 <-- (0) 0;
o1 <-- (1) 0;
}
Literally: “match any addition operation o1, and replace both operands with 0”. Let’s try it on our program:
$ decomp_dbg
...
[decomp]> decompile
Decompiling func_0x00101129
Decompilation complete
[decomp]> print C
xunknown8 func_0x00101129(void)
{
xRam0000000000000000 = 0;
return 0;
}
Great! As expected, the code simplified greatly (since we just removed all additions from our program). Getting to that point was tough, but now that we understand what’s going on it’s getting much easier.
Let’s go back to the original obfuscation and try to match the whole operation:
int4 main(uint4 param_1) {
return (param_1 & 1) * 2 + (param_1 ^ 1);
}
We have several constraints:
- The root of the AST tree that we want to match is a
+operation. - One of
+operands should be^ - The other operand of
+must be* - And the other operand of
+must be&
Let’s try to model this using our grammar knowledge:
{
o_plus(+) <- v1 <- o_mul(*) <- v2 <- o_and(&);
o_plus(+) <- v4 <- o_xor(^);
--
o_plus <-- (0) 0;
o_plus <-- (1) 0;
}
For the action I still use the “zero everything rule”, to make sure the rule still matches. And it does:
$ decomp_dbg
...
[decomp]> print C
xunknown8 func_0x00101129(void)
{
xRam0000000000000000 = 0;
return 0;
}
We’re not done yet - we don’t check the constants or variables anywhere, so our rule will also match (a & 123) * 13 + (b ^ 123) for example.
That’s not what we want. Let’s fix it. There are probably more elegant ways to achieve this, but I did this in the simplest way I could think of:
{
o_plus(+) <- v1 <- o_mul(*) <- v2 <- o_and(&);
o_plus(+) <- v4 <- o_xor(^);
[ o_xor <-(0) 1; o_xor <-(1) vin; | o_xor <-(1) 1; o_xor <-(0) vin; ]
[ o_and <-(0) 1; o_and <-(1) vin; | o_and <-(1) 1; o_and <-(0) vin; ]
[ o_mul <-(0) 2; | o_mul <-(1) 2; ]
--
o_plus <-- (0) 0;
o_plus <-- (1) 0;
}
This uses the “or” syntax that I didn’t mention before - [ ... | ... ]. This means that either the first or the second
statement must match. This rule checks our constraints case by case. For example, [ o_xor <-(0) 1; o_xor <-(1) vin; | o_xor <-(1) 1; o_xor <-(0) vin; ]
means that either first parameter to o_xor is 1, and the second parameter is vin, or the first parameter is vin and the second is 1.
After verifying that this still matches our code, we can replace the “zero everything” action: We want to change the operation to
incrementation, i.e. x + 1. So we want a + operating with one parameter equal to 1, and the other equal to the matched varnode.
Fortunately our top-level opration is already addition, so we just need to replace operands:
{
o_plus(+) <- v1 <- o_mul(*) <- v2 <- o_and(&);
o_plus(+) <- v4 <- o_xor(^);
[ o_xor <-(0) 1; o_xor <-(1) vin; | o_xor <-(1) 1; o_xor <-(0) vin; ]
[ o_and <-(0) 1; o_and <-(1) vin; | o_and <-(1) 1; o_and <-(0) vin; ]
[ o_mul <-(0) 2; | o_mul <-(1) 2; ]
--
o_plus <-- (0) vin;
o_plus <-- (1) 1;
}
A hand-painted artisanal version of the final rule:

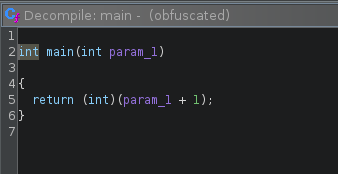
And… that’s it! We can verify that our works correctly now:
[decomp]> print C
int4 func_0x00101129(int4 param_1) {
return (int4)(param_1 + 1);
}
The full rule is, including the XML boilerplate is10:
<experimental_rules>
<rule name="obfuscated_increment" group="analysis" enable="true"><![CDATA[
{
o_plus(+) <- v1 <- o_mul(*) <- v2 <- o_and(&);
o_plus(+) <- v4 <- o_xor(^) <- vin0;
[ o_xor <-(0) 1; o_xor <-(1) vin(==vin0); | o_xor <-(1) 1; o_xor <-(0) vin(==vin0); ]
[ o_and <-(0) 1; o_and <-(1) vin(==vin0); | o_and <-(1) 1; o_and <-(0) vin(==vin0); ]
[ o_mul <-(0) 2; | o_mul <-(1) 2; ]
--
o_plus <-- (0) vin;
o_plus <-- (1) 1;
}
]]></rule>
</experimental_rules>
And the commands to use it:
experimental rules /home/you/xyz/rules.xml
load file /home/you/xyz/obfuscated
adjust vma 0x100000
load addr 0x0101129
decompile
print C
Procedure to apply our rules to the Ghidra UI is slightly different (we need to patch ghidra_process.cc and build.gradle
instead of consolemain.cc and Makefile), but the idea is the same. You can get the patch which makes decompiler use
/etc/ghidra-rules.xml here. Happy hacking.
Conclusion
So that’s it, we created a simple deobfuscation rule for Ghidra decompiler. Since it’s an independent file, you can easily share it with your friends and family - just send them an XML file and they can use it.
As long as they also use your modified version of Ghidra with rules compiled in, of course.
What are the next steps? Frankly, I don’t think there are any. Clearly a lot of work was put into this rule engine, including a custom DSL and AST matcher. But this feature sits in the current state for at least 5 years, and I don’t think Ghidra devs will agree to enable it by default - even if I submitted a PR. It was disabled for a reason.
That would be nice of course - I work with obfuscated code often, and I would love an easier way to extend Ghidra decompiler11. But nowadays I think I would just let plugins register their own hooks and do arbitrary transformations on PCode with Java or Python code. I’m not sure if that’s doable, but one can dream.
Btw: if you use Ghidra, check out my related open-source projects: ghidralib, a Pythonic standard library for Ghidra, and CtrlP, a quick search and command palette plugin.
Or can we? If there is a way, please let me know. It doesn’t invalidate the journey I’ve described in the rest of the post. ↩︎
This is not the official term, but it’s a good name for transformed Pcode. The samentics and amount of available information chanes drastically. ↩︎
One day I will figure out how to force Ghidra to generate proper switches. ↩︎
I plan to document more obscure/obscurish Ghidra features in the future, though. ↩︎
But if you want to load the exported XML, the commands are
restore /path/to/file.xmlandload function yourfunction. ↩︎Someone told me this usage is incorrect, but cambridge dictionary disagrees. ↩︎
To be fair, I recall that one user on Github mentioned in discussion that this feature exist, and that they managed to compile it but had no success with it. That still doesn’t count as an official documentation. ↩︎
I’ve wasted SO MUCH time on that
<. The decompiler is not very talkative, so I was just getting random syntax errors on a few varnode types. ↩︎I wonder if the instability is the reason why this feature was never enabled or officially documented. ↩︎
You may notice there is a small difference to the previous version -
<- vin0and(==vin0). I decided to play it safe, because I’m not 100% sure how term unification works in this language. ↩︎Also a low-level p-code in SSA form link link. And a C AST exposed to scripts link. And a pony. ↩︎